
Migrating Airflow from Amazon ECS to Astronomer
Written by Johnson K.

Companies of any size working with large amounts of data use Airflow to run jobs with complex dependencies on a regular schedule. Whether creating a new Airflow project or working off an existing one, using an Airflow managed service can make it easier to get Airflow up and running at scale. Here at Mage, we use Astronomer Cloud.
Topics Discussed:
What is Airflow?
Our previous setup
Challenges running Airflow in ECS
Managed Airflow alternatives
Our current setup
Migrating to Astronomer Cloud
Deploying Airflow to production using Astronomer Cloud

With Airflow, be the captain, conductor, and manager of tasks that run themselves

What is Airflow?
Apache Airflow is an open-source data orchestration tool for programmatically creating workflows using Python. A workflow includes directed acyclic graphs (DAGs) which have tasks connected to one another but never in a closed loop.
Why should you care?
Workflows can automate and streamline repeatable tasks, increasing productivity and efficiency for your project or business. Creating these workflows without a tool like Airflow can be a difficult and increasingly unmanageable endeavor as the number of tasks grows and the dependencies between tasks become more and more complicated.
If you need to process large amounts of data and have jobs with many steps running on a recurring schedule, Airflow can make your life a lot easier.

How we use Airflow at Mage
Airflow is an essential part of our software stack. Mage is a tool that helps developers use machine learning and their data to make predictions. We use Airflow to orchestrate the steps required in preparing training data, building new machine learning models, deploying machine learning models, processing streamed data, and more.
Airflow is an important part of making sure steps in our workflow happen in a certain order and on a recurring basis.
Options for running Airflow in production
There are many different methods for running Airflow in production, depending on the needs of your project. Though Airflow comes with SQLite by default, it will need a production database like PostgreSQL or MySQL for storing metadata. Amazon’s Relational Database Service (RDS) or Google’s Cloud SQL are two options for hosting the database.
The other components of Airflow can be hosted in different cloud providers or on your own bare-metal server. Here is a non-exhaustive list of various cloud services you can use (get ready for lots of acronyms):
Amazon Web Services
Google Cloud Platform:
Microsoft Azure
Our previous setup — Amazon ECS (Elastic Container Service)
For our previous setup, we used an Amazon ECS cluster running Airflow version 1.10.14. In this ECS cluster, we utilized five services: Workers, Webserver, Scheduler, Flower, and the Celery Executor.

In addition, we had a Redis cluster in Amazon ElastiCache and a PostgreSQL database hosted in Amazon RDS. Refer to the Appendix at the bottom of this post for more details on the Airflow components.
Challenges running Airflow in ECS
As the number of DAGs in our Airflow cluster grew, we noticed that DAGs would sometimes have issues running successfully, or there would be problems with the scheduler. We also had unnecessary costs due to over-provisioned Airflow workers, and it became a hassle to find the right resource allocation through the Amazon ECS UI.
Managing the number of Airflow workers and resources allocated to the various AWS services required for Airflow was a bit cumbersome. We needed a way to easily manage these resources and quickly deploy changes to our infrastructure if necessary. We wanted to be able to scale up Airflow task processing efficiently, effectively, and with as little overhead and maintenance from the team as possible, and we were willing to pay for a managed service to help us with that.
Managed Airflow alternatives

Amazon Managed Workflows for Apache Airflow (MWAA)
MWAA is a managed service in AWS for Apache Airflow. It’s backed by Amazon and meant to integrate with other Amazon services. Google Cloud has their version of a managed service for Airflow in Cloud Composer, but since Mage’s cloud infrastructure is built in AWS (future article on this coming soon), we won’t be mentioning the advantages or disadvantages of using Google Cloud Composer as it wasn’t an option for us.
Pricing for MWAA or Astronomer Cloud isn’t mentioned below because the difference in pricing between the two wasn’t so drastically different that it was a deciding factor in choosing one over the other.
Pros
Autoscaling workers: MWAA is a fully-managed version of Airflow, so it makes it easier to scale up Airflow. If more worker instances are needed to process tasks, MWAA takes care of it automatically and removes workers when they are no longer needed.
Compatibility with other AWS services: MWAA is part the AWS ecosystem and connects well with the tools and other resources required for your workflow if you are already hosting your infrastructure on AWS. For example, it has logging already integrated with Amazon CloudWatch.
Cons
Outdated Airflow Version: At the time of writing (April 2021), the latest Airflow version available in MWAA was 1.10.12. The current latest version of Airflow is 2.0.2. If you wanted to use Airflow 2.0, that’s automatically a dealbreaker for integrating MWAA as your tool for managing Airflow. Though MWAA will inevitably support Airflow 2.0, this may or may not mean that MWAA is slower to adopt the latest Airflow versions.
Required VPC infrastructure: If you require or already have a specific Virtual Private Cloud (VPC) infrastructure in AWS, creating a new MWAA environment may require adjustments to your current VPC or an entirely new VPC. This may not be an issue for you, but it can be a hassle if you just wanted to add the MWAA environment into an existing VPC but weren’t able to due to certain restrictions.
DAGs have to be uploaded to S3: Amazon Simple Storage Service (S3) is used to read all DAGs in MWAA. This could be fine for some workflows, but it could also result in making certain issues harder to debug when new DAGs are deployed. If you want flexibility in where you manage your DAGs and don’t want to go through the added step of uploading them to S3, this requirement for using MWAA may not be worth the additional effort, especially for existing Airflow projects.
Astronomer
Astronomer is a commercial managed Airflow platform that is cloud-agnostic. It can be used with your own cloud environment, whether it is AWS, GCP, or another cloud provider.

Pros
DAGs maintained in Git repositories: You can maintain the folder structure of your current Git repo and dynamically build DAGs without issues potentially caused by importing DAG files to an Amazon S3 bucket. Astronomer allows you to deploy DAGs directly from Git repos.
Cloud-agnostic: Astronomer is not confined to one cloud provider. You can also deploy your Airflow project to Astronomer’s own cloud infrastructure.
Easy initial setup: Astronomer Cloud setup and configuration is fairly straightforward following their documentation and doesn’t require additional security configuration regarding access keys or VPCs, since the Airflow project is hosted in Astronomer’s VPC. However, you can configure your own security settings if you use Astronomer Enterprise.
Customer support: Astronomer users have access to a customer support portal in which they can get quick responses to issues (typically within a business day or two or faster if needed, though it will cost extra) and help with troubleshooting Airflow issues. Astronomer’s business is built around Airflow so their customer support is specialized in Airflow.
CI/CD integration: Airflow deployments through Astronomer can be integrated into CI/CD pipelines using several different CI/CD tools like CircleCI, Jenkins, etc.
Quick deployments: Astronomer’s UI allows you to adjust resources allocated to the scheduler, webserver, and workers all on one page and deploy the changes within a few minutes. Not having to go through several screens to make these changes is convenient if you’re using Astronomer Cloud.
Cons
Limited logs visibility: There may be issues viewing the worker logs, as well as historical scheduler or webserver logs, through the Astronomer UI in Astronomer Cloud.
Log retention period: The log retention period for Astronomer Cloud is 15 days, so if you want access to logs older than that, you may not be able to view them through the Astronomer UI. If you have remote logging enabled, you can still have access to task logs older than 15 days.
Paying for idle resources with the Celery executor: If you’re using the Celery executor and have a lot of resources allocated to your workers but only use your workers for a brief period during the day, you still have to pay for the full capacity of the workers even when they’re not being fully utilized. You do have the option to use the Kubernetes executor, though.
Astronomer currently has two offerings: Cloud and Enterprise.
Astronomer Cloud:
Astronomer Cloud manages all of the infrastructure required to run Airflow. Your Airflow project is run on a Kubernetes cluster and hosted in Astronomer’s Google Cloud environment.
Astronomer Enterprise:
Astronomer Enterprise allows you to run and manage Airflow in your own cloud environment while still utilizing features and support from Astronomer. The enterprise version can be installed on the following Kubernetes environments: AWS Elastic Kubernetes Services (EKS), GCP Google Kubernetes Engine (GKE), or Microsoft Azure Kubernetes Service (AKS).
Astronomer Enterprise gives you more control over your infrastructure hosting Airflow, so you can customize your security settings, such as IAM roles, authentication, and VPC configuration. In addition, you have access to Grafana (a monitoring tool for Airflow metrics), Kibana (a visualization tool for your Airflow logs), and other tools.
Our current setup — Astronomer Cloud

We ultimately ended up going with Astronomer Cloud as our managed service for hosting our Airflow cluster. We did try setting up our Airflow cluster in Amazon MWAA initially because all of our infrastructure was already using AWS, so we thought the transition would be easier.
However, we quickly ran into issues configuring the MWAA environment because we had to create a separate VPC from what our other AWS services were hosted in. Our Airflow setup at the time required a connection to our Redis cluster in Amazon ElastiCache, but we could not make the connection because the Redis cluster was in a different VPC, so we likely needed to create a VPC peering connection. We also had issues building all of our DAGs because we have many dynamically-generated DAGs, and the MWAA workflow requiring DAG files to be uploaded to S3 would have required a lot of big changes to our code.
As for Astronomer Cloud versus Astronomer Enterprise, Astronomer Cloud made more sense for us because we wanted a solution that managed most, if not all, of the infrastructure required for Airflow for us. We had to make some adjustments as mentioned later in this post, but we wouldn’t consider them major changes. As our company grows, Astronomer Enterprise is still an option, and it’s common for companies to start off using Astronomer Cloud and then later switch to Astronomer Enterprise as their needs change.
Migrating to Astronomer Cloud

Upgrading to Airflow 2.0
If you’re not already using Airflow 2.0, you can follow Airflow’s upgrade guide in their documentation to upgrade.
We were using Airflow 1.10.14 and only had to make some minor changes in order to use Airflow 2.0. These are the changes we made:
Replaced all usages of the deprecated
airflow.operators.python_operatorpackage with theairflow.operators.pythonpackage.Removed the
provide_contextargument when calling thePythonOperatorsince that parameter is deprecated and no longer required in Airflow 2.0.Updated environment variables related to remote logging. We had remote logging enabled in Amazon S3, so we had to update these environment variables:
i. AIRFLOW__CORE__REMOTE_LOGGING —> AIRFLOW__LOGGING__REMOTE_LOGGING
ii. AIRFLOW__CORE__REMOTE_BASE_LOG_FOLDER —> AIRFLOW__LOGGING__BASE_LOG_FOLDER
iii. AIRFLOW__CORE__REMOTE_LOG_CONN_ID —> AIRFLOW__LOGGING__REMOTE_LOG_CONN_ID
iv. AIRFLOW__CORE__LOGGING_LEVEL —> AIRFLOW__LOGGING__LOGGING_LEVEL
There are other Airflow environment variables that were deprecated in version 2.0, so you may want to check the docs to see if your existing project is using any of them.
Removing and updating files
We were building our own custom Docker image for setting up the various Airflow services using a Dockerfile with the base image puckel/docker-airflow:1.10.9. This Dockerfile had an ENTRYPOINT that pointed to an entrypoint.sh script which defined several environment variables and installed Python packages.
Since Astronomer manages their own Docker images with all the Airflow configuration for the webserver, scheduler, and Postgres database out-of-the-box, we were able to delete the following files from our root Airflow directory:
entrypoint.shairflow.cfgdocker-compose.yml
We no longer needed all the instructions in the Dockerfile, so we deleted everything inside it and simply replaced it with one command:
FROM quay.io/astronomer/ap-airflow:2.0.0-4-buster-onbuild
You can check Astronomer’s Docker container registry at quay.io to find the latest Airflow Docker image. One of the packages in our requirements.txt file was apache-airflow==1.10.14, but we removed that since Astronomer's Docker images already have Airflow installed.
We had used a Redis cluster in Amazon ElastiCache to dynamically build DAGs, so an Airflow connection to Redis was required. This worked well for us at the time because our Airflow services and Redis cluster were all hosted on the same Virtual Private Cloud (VPC) in AWS.
Since production Airflow projects are managed in Astronomer’s own cloud environment for Astronomer Cloud, there were issues with Airflow connecting to our ElastiCache Redis cluster. Instead of trying to create a VPN connection to our VPC containing the Redis cluster, we took advantage of the built-in Airflow Variables as it also acts as a key-value store. This required refactoring all the areas of our code where we were setting Redis keys and getting Redis values.
from airflow.models import Variable
from datetime import datetime, timedelta
import json
class AirflowVariable():
def get_json_variable(self, key):
return json.loads(Variable.get(
key,
default_var='{}'),
).get('value', None)
def set_json_variable(
self,
key,
value,
expires_after=timedelta(hours=1),
):
Variable.set(
key,
json.dumps({
'value': value,
'expires_at': (
datetime.utcnow() + expires_after,
).isoformat(),
}),
)An example of Airflow variable helper methods for storing values as json
Installing and using Astronomer locally
Follow the steps in Astronomer’s CLI Quickstart Guide to install and start Astronomer locally, taking note of the items below.
When initializing an Airflow project on Astronomer, enter your existing Airflow root directory where the
dagsfolder is located in. You don't need to create a new directory andcdinto it, since you already have an existing Airflow project.
airflow # root directory
├── dags
├── Dockerfile
├── README.md
└── requirements.txtA simple Airflow project folder structure
Run the following command:
astro dev initSome new files and folders will be generated automatically. We didn’t need to include additional files, plugins, OS-level packages, or Airflow connections, so our
includeandpluginsfolders were empty and thepackages.txtfile blank.We used to have a Redis connection as described earlier in this post, but since it was no longer needed, our
airflow_settings.yamlfile was also blank.If you previously had Docker containers running Airflow locally before installing Astronomer, make sure you stop those containers or change their ports in the
.astro/config.ymlfile before running Airflow locally with Astronomer using theastro dev startcommand. There is a note with more details in the "Start Airflow Locally" step of the Astronomer Quickstart Guide.Earlier in this post, we mentioned that one of the files we deleted was the
docker-compose.ymlfile. We had used it to build and deploy Docker images for the Airflow webserver, scheduler, and worker locally, but with Astronomer, it conveniently takes care of this for us without the need for adocker-compose.ymlfile. We just need to specify the Docker image (and Airflow version) that we want to use from Astronomer's container registry inside of the Dockerfile.
Deploying Airflow to production using Astronomer Cloud
You can deploy your Airflow project to production by creating an Astronomer workspace and following the steps in Astronomer’s deployment guide.
Astronomer lets you choose between three executors to execute the tasks within your DAGs. These are the Kubernetes, Celery, and Local executors. You won’t be able to change the executor through the
AIRFLOW__CORE__EXECUTORenvironment variable because Astronomer sets it automatically.At Mage, we use the Celery executor, and it has worked well for us so far, though we would consider switching to the Kubernetes executor in the future if the situation called for it.
Astronomer production deployment settings
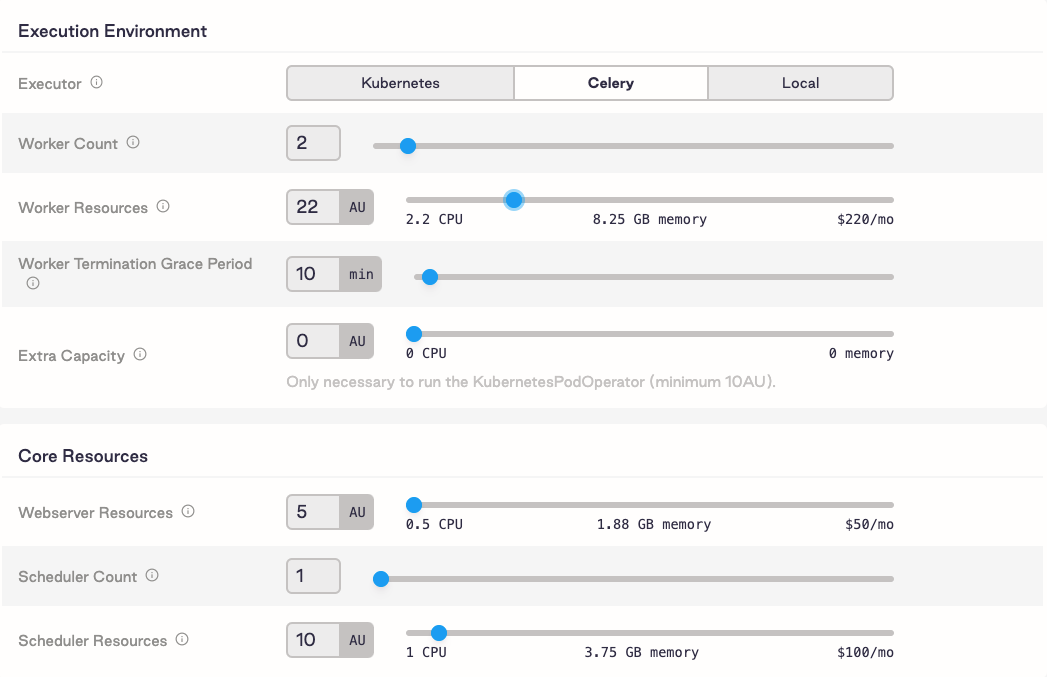
The screenshot above shows how much resources we allocated to our Celery workers, the webserver, and the scheduler. This setup costs $670/month, but you can see the monthly cost for other resource allocations when you adjust the sliders for the settings.
This required some experimentation to see what made sense for us while trying to avoid over-provisioning resources and spending money we didn’t need to. For context, we have around 300 DAGs that get run daily at the time of writing.
The webserver and scheduler are at their default levels, so we didn’t have to increase resources for those yet.
Environment variables to take into account for scalability
Since we removed the
airflow.cfgfile and no longer need it when using Astronomer, we make changes to environment variables (the different methods are explained in Astronomer's documentation) if we want to update the Airflow configuration.AIRFLOW__CORE__PARALLELISM- Max number of overall task instances to run in parallel; default of 32.AIRFLOW__CORE__DAG_CONCURRENCY- Number of task instances to run concurrently in one DAG; default of 16.AIRFLOW__CELERY__WORKER_CONCURRENCY- Number of tasks each Celery worker can process at a time; default of 16. We initially set this way too high given the limited resources allocated to one worker, so be careful not to set an arbitrarily high number or your DAGs may not get properly executed. We have this value set at 30 in our current setup.AIRFLOW__CORE__DAGBAG_IMPORT_TIMEOUT- Seconds before timing out a Python file import; default of 30. If you have dynamic DAGs that may take some time to parse, increase this value. We have it set to 3600.Depending on how many DAGs you have, the number of Airflow workers, and the amount of resources allocated to each worker, you’ll need to adjust the environment variables above to accommodate your Airflow configuration. Refer to Airflow’s configuration reference for all the other environment variables you can use, as well as Astronomer’s guide on scaling out Airflow for more details.
Closing thoughts

Our Airflow setup and configuration isn’t perfect and we’ll inevitably have to make adjustments as our company grows. But if you’re planning on moving your Airflow project to a managed solution, hopefully this post saved you the headache of dealing with some of the issues we ran into and may serve as a starting point. If you have any questions related to this post or about our company or just found some errors you wanna tell us about, feel free to email eng@mage.ai. We are always open to all types of feedback and looking for ways to improve our content!
Airflow Components Appendix
Workers: Workers function to execute the logic of tasks. By listening to message queues, workers pull the desired tasks of a DAG and process them.
Webserver: The Webserver UI (user interface) of Airflow provides the ability to control and visualize aspects of each pipeline. Two important functions that the Webserver provides are monitoring DAGs and providing DAG visualization tables. This shows each DAG’s runs and the status of every task’s runs.
Scheduler: The Airflow scheduler is a Python process which checks the code in the Airflow DAG folder. The scheduler manages DAG runs, tasks, and the storing of DAGs. From there, it decides which DAGs should run on each pool and will monitor the DAGs to see which are running successfully and which need to be executed or retired.
Flower:Flower is a tool which monitors and administers Celery clusters — distributed task queues based on distributed message passing.
Celery Executor: The executor is responsible for running each task. There are various types of executors, but we used the Celery executor as it allowed for horizontal scaling of workers without the need for Kubernetes. Astronomer has a great guide in their documentation explaining Airflow executors.
Redis: We used Redis (an in-memory data store) as the Celery broker for message transports. We also used Redis to dynamically build DAGs by regularly making calls to our backend to retrieve live model data and storing it in Redis. The DAGs would get updated or created based off of this data in Redis.
PostgreSQL: This was our metadata database used to store configurations, variables, tasks, schedule intervals, and other relevant data.